
SEO pókok: Miért fontosak a weboldalad számára
A pókok olyan botok, amelyeket spam küldésére hoztak létre, és komoly problémákat okozhatnak a vállalkozásodnak. Tudj meg többet róluk a cikkből.
4 perc olvasás
SEO
DigitalMarketing
+3
Tudja meg, miért nevezik a webes robotokat pókoknak, hogyan működnek, és milyen kritikus szerepet töltenek be a keresőmotorok indexelésében. Fedezze fel a webes feltérképezés technikai mechanizmusait 2025-ben.
A webes robotokat azért nevezik pókoknak, mert rendszerezetten haladnak végig a weben, egyik oldalról a másikra követve a hivatkozásokat, hasonlóan ahhoz, ahogy egy pók mozog a hálóján. A 'pók' kifejezés találó metafora ezekre az automatizált botokra, amelyek bejárják a weboldalak összekapcsolt hálózatát, hogy felfedezzék, indexeljék és rendszerezzék a tartalmakat a keresőmotorok számára.
A “pók” elnevezés a webes robotokra egy találó metaforikus összehasonlításból ered, amely párhuzamot von a robotok internetes navigációja és a valódi pókok hálón való mozgása között. Ahogyan a pók egy bonyolult hálót sző, hogy információt gyűjtsön környezetéről, a webes robotok is végigjárják a World Wide Web összekapcsolt hivatkozásainak hálóját, hogy felfedezzék, elemezzék és rendszerezzék a digitális tartalmakat. A metafora különösen találó, mert mindkét szereplő rendszerezetten, összetett hálózatokon keresztül mozog, útvonalakat követve új pontokat ér el, és információt gyűjt. Ez az elnevezési konvenció annyira beépült a technológiába, hogy a “pók”, “robot” és “bot” kifejezéseket gyakran felváltva használják a webindexelés technológiájának említésekor. A pók hálójának és az internet szerkezetének vizuális és fogalmi hasonlósága intuitívvá és emlékezetessé teszi ezt a terminológiát mind a szakemberek, mind az általános felhasználók számára.
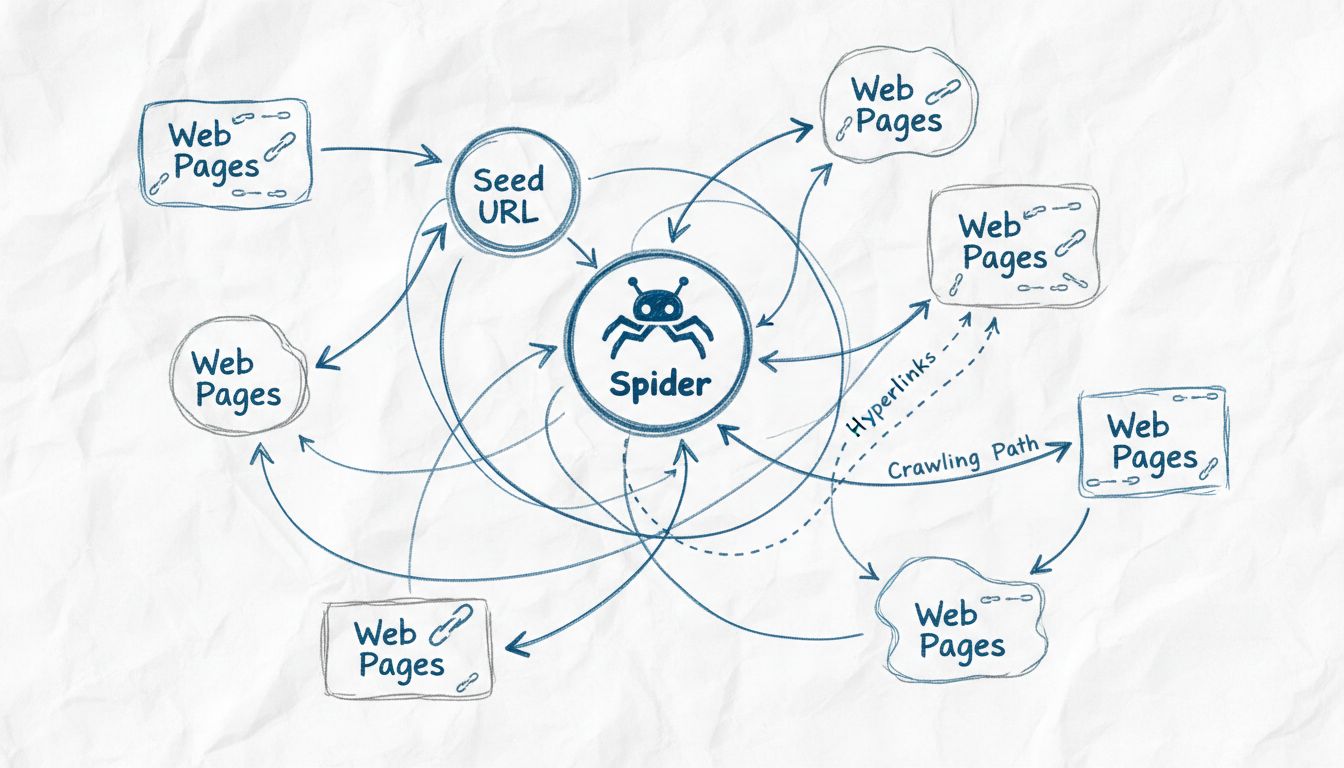
A webes pókok egy kifinomult, mégis rendszerezett folyamat szerint működnek, amely egyetlen belépési ponttal, az úgynevezett “mag URL-lel” indul. Erről a kiindulási helyről a pók elemzi a weboldal HTML-kódját, és kinyeri az ott található összes hivatkozást. Ezeket a linkeket követve új oldalakat ér el, majd a folyamatot ismétli, így folyamatosan bővíti elérését az egész weben. Ez a módszeres megközelítés lehetővé teszi, hogy a pókok emberi beavatkozás nélkül fedezzenek fel akár több millió összekapcsolt oldalt is. A pók fenntart egy úgynevezett “feltérképezési határterületet”, vagyis egy olyan URL-sorban álló listát, amelyen azok a webcímek szerepelnek, amelyeket már felfedezett, de még nem látogatott meg. Speciális feltérképezési szabályok és algoritmusok alapján dönti el, mely URL-eket célozza meg következőként, figyelembe véve például az oldal fontosságát, frissítési gyakoriságát és a keresőmotor indexelési céljaihoz való relevanciáját.
Állítsd be a fejlett nyomkövetést percek alatt. Bankkártya nem szükséges.
A modern webes pókok kifinomult technikai architektúrára épülnek, amely lehetővé teszi számukra, hogy hatékonyan dolgozzák fel a hatalmas mennyiségű adatot. A webes robotok főbb összetevői közé tartozik az URL-frontier menedzsment rendszer, amely szervezi és priorizálja a feltérképezendő URL-eket; a letöltő mechanizmus, amely nagy sebességgel tölti le az oldal tartalmát; a feldolgozó motor, amely kinyeri a linkeket és a metaadatokat a HTML-ből; valamint az indexelőrendszer, amely a feldolgozott információkat keresésre alkalmas formában tárolja. A webes pókoknak udvariassági szabályokat is be kell tartaniuk, hogy ne terheljék túl a céloldalakat kérésekkel; újralátogatási szabályokat, hogy eldöntsék, milyen gyakran térjenek vissza egy-egy oldalhoz frissítések miatt; és szelekciós szabályokat, hogy a legértékesebb hivatkozásokat kövessék. A modern pókok képesek JavaScript- és AJAX-tartalmak feldolgozására is, bár továbbra is az alap HTML-t részesítik előnyben a megbízható tartalomfelfedezés miatt. A korszerű feltérképezés elosztott módon zajlik, vagyis a nagyobb pókok több szerveren párhuzamosan működnek, így egyszerre több webhelyet képesek feltérképezni, ami nagyságrendekkel növeli hatékonyságukat és lefedettségüket.
Bár a “pók” és a “robot” szavakat gyakran felváltva használják, érdemes tudni, hogy ugyanazt a technológiát jelentik eltérő elnevezéssel. A webes pókok azonban jelentősen különböznek a webes scraperektől, amelyeket olykor összetévesztenek a robotokkal. A fő különbség a célban és a működési körben rejlik: a webes robotok általános információgyűjtésre törekednek a weboldalakról és azok szerkezetéről, széles körben követik a linkeket, hogy átfogó indexeket építsenek. A pókok, amikor keresőmotorok használják őket, elsősorban a szöveges tartalom indexelésére koncentrálnak, hogy az kereshetővé és felfedezhetővé váljon. Ezzel szemben a scraperek célzott eszközök, amelyek egyes konkrét adatokat – például árakat, elérhetőségeket vagy véleményeket – gyűjtenek ki weboldalakról. A scraperek általában konkrét oldalakat vagy adatokat céloznak, nem járják be széles körben a webet. Továbbá, a pókok és robotok általában tiszteletben tartják a robots.txt fájlokat és a weboldalak felhasználási feltételeit, míg a scraperek gyakran nem. Ezeknek a különbségeknek a megértése kulcsfontosságú a weboldaltulajdonosok és fejlesztők számára, akik szabályozni szeretnék, hogy tartalmaikat hogyan férik hozzá és indexelik automatizált rendszerek.
Értesülj elsőként az új funkciókról és termékfrissítésekről.
A webes pókok alapvető fontosságúak abban, ahogyan a keresőmotorok működnek és értéket nyújtanak a felhasználók számára világszerte. Pókok folyamatos feltérképezése és indexelése nélkül a keresőmotoroknak nem lenne módjuk tudni, hogy milyen weboldalak léteznek, milyen tartalommal bírnak, vagy mennyire relevánsak a felhasználói lekérdezésekhez. Amikor egy pók feltérképez egy oldalt, számos tényezőt vizsgál, például az oldal szerkezetét, a tartalom relevanciáját, a kulcsszavak használatát és a felhasználói élmény jeleit. Ezeket az információkat hatalmas indexekben tárolják, amelyeket a keresőmotorok arra használnak, hogy a lekérdezésekhez a legrelevánsabb találatokat társítsák. A pók feltérképezésének minősége és gyakorisága közvetlenül befolyásolja, hogy milyen gyorsan jelenik meg az új tartalom a keresési eredmények között, valamint hogy mennyire pontosan rangsorolják az oldalakat. Az olyan keresőmotorok, mint a Google, Bing, Baidu és Yahoo mind saját, egyedi algoritmusokkal és stratégiákkal rendelkező pók-botokat működtetnek – például Googlebot, Bingbot, Baiduspider és Slurp –, amelyeket kifejezetten a keresőjük céljaihoz és felhasználói köréhez optimalizáltak.
| Pók-bot | Keresőmotor | Elsődleges funkció | Feltérképezési stratégia | Főbb jellemzők |
|---|---|---|---|---|
| Googlebot | Weboldalak indexálása a Google keresőhöz | Elosztott feltérképezés mobil és asztali változattal | JavaScript feldolgozás, mobil-előnyben indexelés, crawl budget kezelése | |
| Bingbot | Microsoft Bing | Weboldalak indexálása a Bing keresőhöz | Párhuzamos feltérképezés több szerveren | Hatékony sávszélesség-használat, robots.txt tisztelete, több tartalomtípus támogatása |
| Baiduspider | Baidu | Weboldalak indexálása a Baidu keresőhöz | Kínai nyelvű tartalomra optimalizált | Ázsiai webtartalomra specializált, kezeli az egyszerűsített és hagyományos kínait |
| DuckDuckBot | DuckDuckGo | Weboldalak indexálása adatvédelmi fókuszú kereséshez | Udvarias feltérképezés, hangsúly a magánszférán | Minimális adatgyűjtés, tiszteletben tartja a felhasználói adatvédelmet |
| YandexBot | Yandex | Weboldalak indexálása a Yandex keresőhöz | Elosztott feltérképezés régiós optimalizációval | Orosz és kelet-európai tartalomra optimalizált |
A webhelytulajdonosoknak számos eszköz és stratégia áll rendelkezésükre, hogy optimalizálják a pókok feltérképezését és indexelését. Egy átfogó sitemap.xml fájl létrehozása világos térképet ad a pókoknak az indexelendő oldalakról, javítva a feltérképezés hatékonyságát és biztosítva, hogy egy fontos oldal se maradjon ki. A meta tagek – például a cím és leírás – optimalizálása segít a pókoknak jobban megérteni az oldal tartalmát, és javítja a keresési megjelenést. A megfelelően beállított robots.txt fájl lehetővé teszi, hogy a webhelytulajdonosok a fontos tartalom felé irányítsák a pókokat, miközben kizárják például az adminisztrációs felületeket vagy a duplikált tartalmakat. A rendszeres frissítés és új tartalom hozzáadása arra ösztönzi a pókokat, hogy gyakrabban térjenek vissza az oldalra, így az indexek naprakészek maradnak, és javul a keresőben való láthatóság. Fontos a tiszta, logikus oldalstruktúra és a jól felépített hierarchikus navigáció is, hogy a pókok könnyen megtalálják az összes oldalt. Az oldalbetöltési sebesség javítása kritikus, mivel a pókok számára korlátozott az úgynevezett crawl budget – vagyis a keresőmotor által adott erőforrások mennyisége adott oldal feltérképezésére –, így a gyorsabb oldalak lehetővé teszik, hogy a pók több tartalmat dolgozzon fel ugyanazon költségkeret mellett.
A pókok fejlettsége ellenére számos technikai kihívással néznek szembe, amelyek korlátozhatják hatékonyságukat. A JavaScript által generált dinamikus tartalom komoly akadályt jelent, mivel nem minden pók képes végrehajtani a JavaScript-kódot, hogy úgy jelenítse meg az oldalakat, ahogy azt a felhasználók látják. A webhelyek által alkalmazott lekérdezési korlátok szintén megszabhatják, hogy a pók mennyi kérést küldhet egy adott időszakban, ami akadályozhatja a nagy weboldalak teljes feltérképezését. A CAPTCHA-k és más bot-ellenes megoldások elzárhatják a pók elől a tartalmat, bár a legitim keresőmotorok pók-botjai általában engedélyezettek. A több URL-en megjelenő duplikált tartalom összezavarhatja a pókokat abban, hogy melyik változatot indexeljék, ami ronthatja az oldal keresőbeli láthatóságát. Az úgynevezett “crawler trap”-ek – szándékos vagy véletlen végtelen hurkok a webhely szerkezetében – pazarolhatják a pók erőforrásait, és felélhetik a crawl budgetet anélkül, hogy hasznos indexelést végeznének. A webes tartalom exponenciális növekedése miatt a pókok lehetőségei is végesek, ezért kifinomult algoritmusokra van szükség, hogy a legfontosabb tartalom kapjon prioritást. A jelszóval védett és hitelesítést igénylő oldalak továbbra is nagyrészt elérhetetlenek a nyilvános pókok számára, így ezek a tartalmak ritkán kerülnek indexelésre.
A webes pók technológia folyamatosan fejlődik, ahogy az internet egyre nagyobbá és összetettebbé válik. A modern pókok egyre inkább képesek kezelni a fejlett webes technológiákat, például az egyoldalas alkalmazásokat, progresszív webappokat és dinamikus tartalom-megjelenítést. A mesterséges intelligencia és a gépi tanulás egyre inkább beépül a pók-algoritmusokba, hogy jobban értsék a tartalom kontextusát, a felhasználói szándékokat és az oldal minőségét. A generatív AI térnyerése új igényeket támaszt a webes feltérképezéssel szemben, mivel ezeknek a rendszereknek folyamatosan friss, releváns és pontos információkra van szükségük a hatékony működéshez. A vállalati webes robotok is egyre kifinomultabbá váltak, lehetővé téve a cégek számára, hogy saját weboldalaikat belső kereséshez, tartalomkezeléshez vagy teljesítménymonitorozáshoz feltérképezzék. A feltérképezési hatékonyság egyre fontosabb, ahogy a weboldalak mérete és összetettsége nő, a pókok pedig okosabb prioritási algoritmusokat alkalmaznak, hogy minden lekérdezésből a lehető legtöbbet hozzák ki. Az adatvédelem is formálja a pókfejlesztést, egyre nagyobb hangsúlyt kap a felhasználói magánszféra tiszteletben tartása, miközben továbbra is lehetővé teszik a hatékony tartalomfelfedezést és indexelést. A jövőben a webes pókok várhatóan még intelligensebbé és hatékonyabbá válnak, fejlett technológiák segítségével navigálva a bonyolult digitális térben, miközben tiszteletben tartják a webhelyek szabályait és a felhasználók adatvédelmét.
Ahogyan a webes pókok rendszerezetten feltérképezik és indexelik az egész webet, a PostAffiliatePro ugyanilyen szervezetten követi és optimalizálja az összes affiliate kapcsolatot a hálózatában. Fejlett nyomkövető technológiánk garantálja, hogy egyetlen jutalék se maradjon feljegyzetlenül, és egyetlen lehetőség se vesszen el.
A pókok olyan botok, amelyeket spam küldésére hoztak létre, és komoly problémákat okozhatnak a vállalkozásodnak. Tudj meg többet róluk a cikkből.
A robotok (crawlers) adatokat és információkat gyűjtenek az internetről weboldalak meglátogatásával és az oldalak tartalmának olvasásával. Tudjon meg többet ról...

Ismerje meg, hogyan működnek a webes keresőrobotok a kezdő URL-ektől az indexelésig. Értse meg a technikai folyamatokat, a keresőrobotok típusait, a robots.txt ...
Csatlakozzon elégedett ügyfeleink közösségéhez és nyújtson kiváló ügyfélszolgálatot a Post Affiliate Pro-val.
Sütik Hozzájárulás
A sütiket használjuk, hogy javítsuk a böngészési élményt és elemezzük a forgalmunkat. See our privacy policy.