
Robotok és szerepük a keresőmotorok rangsorolásában
A robotok (crawlers) adatokat és információkat gyűjtenek az internetről weboldalak meglátogatásával és az oldalak tartalmának olvasásával. Tudjon meg többet ról...
5 perc olvasás
SEO
Crawlers
+4


Ismerje meg, hogyan működnek a webes keresőrobotok a kezdő URL-ektől az indexelésig. Értse meg a technikai folyamatokat, a keresőrobotok típusait, a robots.txt szabályokat és hogy ezek miként befolyásolják az SEO-t és az affiliate marketinget.
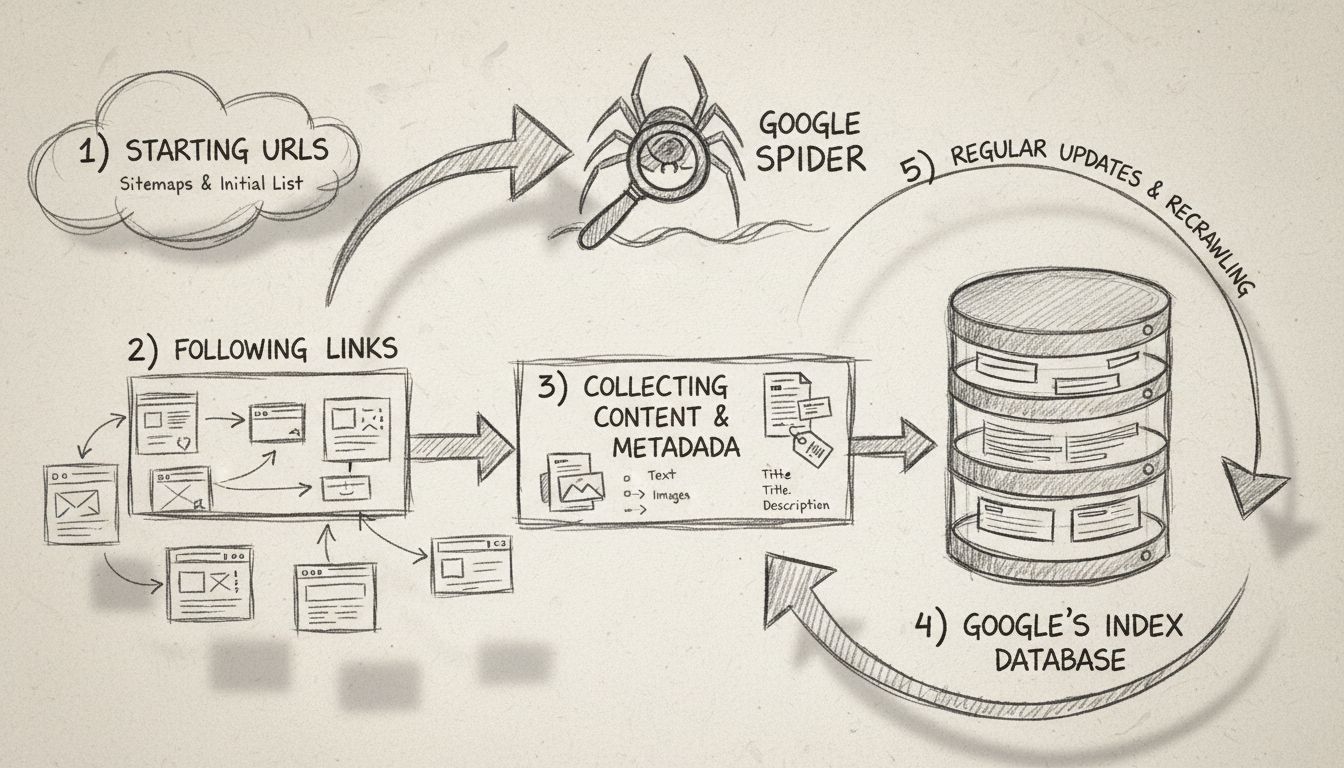
A webes keresőrobotok HTTP-kéréseket küldenek weboldalakra kiinduló (seed) URL-ekből, hiperhivatkozásokat követve fedeznek fel új oldalakat, HTML-tartalmat elemeznek információk kinyerésére, betartják a robots.txt szabályokat, és az összegyűjtött adatokat kereshető indexekben tárolják. Rendszeresen látogatják az oldalakat, metaadatokat és linkeket gyűjtenek, majd ismétlik a folyamatot, hogy a keresőmotorok adatbázisai naprakészek maradjanak.
A webes keresőrobotok, más néven spiderek vagy botok, automatizált programok, amelyek rendszerezetten böngészik az internetet webes tartalom felfedezése, letöltése és elemzése céljából. Ezek az intelligens ügynökök alkotják a keresőmotorok infrastruktúrájának gerincét, lehetővé téve a Google, Bing és más keresők számára, hogy milliárdnyi weboldal átfogó indexeit hozzák létre. A keresőrobotok elsődleges célja, hogy összegyűjtsék és rendszerezzék a webhelyek információit, így a keresőmotorok gyorsan tudnak releváns találatokat adni, amikor a felhasználók keresést indítanak. Keresőrobotok nélkül a keresőmotorok nem tudnák felfedezni az új tartalmakat, vagy naprakészen tartani az indexeiket a legfrissebb online információkkal.
A keresőrobotok jelentősége messze túlmutat a puszta keresési funkción. Alapját képezik számos digitális alkalmazásnak, beleértve az árösszehasonlító oldalakat, tartalomaggregátorokat, piackutató platformokat, SEO elemző eszközöket és webarchiváló szolgáltatásokat. Az affiliate marketingeseknek és hálózatüzemeltetőknek – például a PostAffiliatePro felhasználóinak – alapvető, hogy értsék a keresőrobotok működését annak érdekében, hogy az affiliate tartalmak, termékoldalak és promóciós anyagok megfelelően felfedezhetők és indexelhetők legyenek a keresőmotorok számára. Ez a láthatóság közvetlenül befolyásolja az organikus forgalmat, a lead generálást és végső soron az affiliate jutalékszerzési lehetőségeket.
A webes keresőrobotok módszeres és strukturált folyamatot követnek az internet rendszerezett feltérképezésére. A folyamat kezdő URL-ekkel (seed URL) indul, amelyek ismert kiindulópontok, például webhely kezdőlapja, XML oldaltérképek vagy korábban feltérképezett oldalak. Ezek szolgálnak a robot induló pontjaként a weben való utazásához. A robot egy folyamatosan bővülő URL-várólistát tart fenn, amelyet “feltérképezési határnak” (crawl frontier) is neveznek, és amelyre új linkek kerülnek fel a feltérképezés során.
Amikor a keresőrobot elér egy URL-t, HTTP-kérést küld az azt tároló webszervernek. A szerver visszaküldi az oldal HTML tartalmát – hasonlóan ahhoz, ahogy egy böngésző tölti be az oldalt. Ezután a robot elemzi a HTML kódot, hogy értékes információkat nyerjen ki, beleértve az oldalszöveget, meta tageket (pl. cím és leírás), képeket, videókat, és legfőképp más oldalakra mutató hiperhivatkozásokat. Ez a linkkinyerés alapvető, mert lehetővé teszi, hogy a robot új, eddig nem látogatott URL-eket fedezzen fel, amelyeket később hozzáad a várólistához.
| A keresőrobot folyamata | Leírás | Fő lépések |
|---|---|---|
| Inicializálás | A feltérképezés indítása | A kezdő URL-ek betöltése, várólista létrehozása |
| Kérés & Letöltés | Oldaltartalom lekérése | HTTP-kérések küldése, HTML-válaszok fogadása |
| HTML elemzés | Oldalstruktúra feldolgozása | Szöveg, metaadat, linkek, média kinyerése |
| Linkek kinyerése | Új URL-ek keresése | Hiperhivatkozások azonosítása, várólistához adás |
| robots.txt ellenőrzése | Szabályok betartása | Feltérképezési engedélyek ellenőrzése oldal előtt |
| Tartalom tárolása | Információk mentése | Adatok indexelése kereshető adatbázisba |
| Prioritáskezelés | Következő oldalak kiválasztása | URL-ek rangsorolása fontosság és relevancia szerint |
| Ismétlés | Folyamat folytatása | Következő URL feldolgozása |
Mielőtt egy robot meglátogatna egy új URL-t egy domainen, a felelős keresőrobotok ellenőrzik a domain gyökérkönyvtárában található robots.txt fájlt. Ebben a fájlban a webhely-tulajdonosok adnak utasításokat a robotok számára arról, hogy mely oldalakat lehet feltérképezni és melyeket kell elkerülni. Például egy webhely-tulajdonos robots.txt-vel megtilthatja a keresőrobotoknak, hogy érzékeny oldalakat, duplikált tartalmakat vagy erőforrásigényes szekciókat keressenek fel, amelyek túlterhelhetnék a szervert. A megbízható keresőrobotok tiszteletben tartják ezeket a szabályokat a jó kapcsolat érdekében és hogy ne okozzanak teljesítményproblémákat.
Állítsd be a fejlett nyomkövetést percek alatt. Bankkártya nem szükséges.
A modern keresőrobotok jelentősen fejlődtek, hogy képesek legyenek kezelni a mai weboldalak összetettségét. Számos webhely JavaScriptet használ a tartalom dinamikus betöltésére, vagyis a kezdeti HTML válaszban nem található meg minden tartalom. A fejlett keresőrobotok ma már headless böngészőket alkalmaznak a JavaScript futtatására és a dinamikusan betöltött tartalom rögzítésére, amelyet a hagyományos keresőrobotok nem látnak. Ez elengedhetetlen egyoldalas alkalmazások, interaktív dashboardok és modern, kliensoldali renderelésű webes alkalmazások feltérképezéséhez.
A keresőrobotok kifinomult prioritáskezelő algoritmusokat alkalmaznak, hogy hatékonyan használják fel a “feltérképezési költségkeretet” – vagyis azt a korlátozott oldalszámot, amit adott idő alatt bejárhatnak. Ezek az algoritmusok számos tényezőt figyelembe vesznek, mint például az oldal tekintélyét (visszamutató linkek minősége és mennyisége), a belső linkstruktúrát, a tartalom frissességét, a forgalom nagyságát és a domain hírnevét. A nagy tekintélyű és gyakran frissített oldalakhoz gyakrabban térnek vissza a robotok, míg a kevésbé fontos vagy statikus oldalakat ritkábban vagy egyáltalán nem keresik fel. Ez az intelligens prioritáskezelés biztosítja, hogy a keresőrobotok erőforrásaikat a legértékesebb és leggyakrabban változó tartalomra összpontosítsák.
Feltérképezési késleltetés és sebességkorlátozás fontos eszközök annak érdekében, hogy a keresőrobotok ne terheljék túl a webkiszolgálókat. A felelős robotok szüneteket tartanak a kérések között, illetve betartják a robots.txt-ben megadott crawl-delay utasításokat. Ez az udvarias magatartás óvja a webhely teljesítményét és a felhasználói élményt, hiszen a keresőrobot-forgalom nem fog túl sok szerver erőforrást felhasználni. A lassan betöltődő vagy hibát adó weboldalak esetén a robotok automatikusan csökkentik a feltérképezési gyakoriságot, hogy elkerüljék a problémák okozását.
A különböző keresőrobotok eltérő szerepeket töltenek be a digitális ökoszisztémában. Az általános webes keresőrobotokat a nagy keresőmotorok telepítik, hogy válogatás nélkül feltérképezzék az egész internetet, átfogó indexeket készítve, amelyek a keresési találatokat szolgáltatják. Ezek a robotok a maximális lefedettségre vannak optimalizálva, folyamatosan működnek, hogy új tartalmakat fedezzenek fel és frissítsék az indexeket. A vertikális vagy specializált keresőrobotok meghatározott iparágakra vagy tartalomtípusokra összpontosítanak, például álláskereső robotok az állásportálokon, árösszehasonlító robotok e-kereskedelmi árak begyűjtésére, vagy tudományos robotok akadémiai cikkek, publikációk indexelésére.
Az inkrementális keresőrobotok a hatékonyságra specializálódtak: kizárólag az új vagy nemrégiben módosított tartalmakra koncentrálnak ahelyett, hogy folyamatosan újra feltérképeznék az egész webhelyet. Ez jelentősen csökkenti a szerverterhelést és a sávszélesség-felhasználást, miközben az index viszonylag naprakész marad. A fókuszált keresőrobotok intelligens algoritmusokat használnak, hogy meghatározott témák vagy kulcsszavak szerint keressenek tartalmat, előnyben részesítve azokat az oldalakat, ahol nagy valószínűséggel található releváns információ. A valós idejű keresőrobotok folyamatosan monitorozzák a weboldalakat és valós vagy közel valós időben frissítik az összegyűjtött adatokat, ezért ideálisak híraggregátorokhoz és közösségi médiafigyelő alkalmazásokhoz.
A párhuzamos és elosztott keresőrobotok a keresőrobot-architektúra infrastruktúraigényes végéhez tartoznak. A párhuzamos keresőrobotok több gépen vagy szálon futnak, jelentősen növelve a feltérképezési sebességet és kapacitást. Az elosztott keresőrobotok a munkaterhelést több szerver vagy adatközpont között osztják szét, így hatékonyan képesek hatalmas mennyiségű adat feldolgozására. A nagy keresőmotorok, például a Google, elosztott keresőrobot-architektúrát használnak az internet milliárdnyi oldalának kezelésére.
Értesülj elsőként az új funkciókról és termékfrissítésekről.
A keresőrobotok alapvető szerepet játszanak a keresőoptimalizálásban, hiszen ők határozzák meg, hogy mely oldalak kerülnek indexelésre és hogyan értelmezi a keresőmotor a tartalmat. Ha a keresőrobotok nem férnek hozzá egy oldalhoz, az az oldal nem fog megjelenni a találatok között, függetlenül a minőségétől vagy relevanciájától. Gyakori feltérképezési problémák, amelyek gátolják az indexelést: robots.txt szabályok által blokkolt oldalak, hibás belső linkek (404-es hibák), lassú oldalbetöltés (időkorlátot túllépő robotok), vagy JavaScript renderelési gondok, amelyek miatt a tartalom nem látható a robotok számára.
A webhelytulajdonosok többféle módszerrel optimalizálhatják a keresőrobotok hozzáférését. Átlátható webhely-architektúra logikus navigációval segíti a robotokat az oldalak közötti kapcsolatok és fontosság megértésében. Belső linkelés mutatja meg a robotoknak, mely oldalak a legfontosabbak, és segít hatékonyan elosztani a feltérképezési költségkeretet az oldalon belül. Az XML oldaltérképek felsorolják az összes fontos oldalt, biztosítva, hogy a keresőrobotok ne hagyjanak ki tartalmat akkor sem, ha a webhely nagy vagy összetett. Gyors oldalbetöltés arra ösztönzi a robotokat, hogy több oldalt látogassanak meg az adott időkereten belül, míg a friss, rendszeresen frissített tartalom arra utal, hogy az oldal gyakrabban érdemel feltérképezést.
Az affiliate marketingesek számára, akik például a PostAffiliatePro-t használják, elengedhetetlen a helyes feltérképezhetőség az organikus forgalom növeléséhez. Ha affiliate termékoldalai, összehasonlító cikkei és promóciós tartalmai megfelelően feltérképezhetők és indexelhetők, esélyük van megjelenni a keresési találatok között és releváns forgalmat vonzani. Rossz feltérképezhetőség kihagyott indexelési lehetőségeket és csökkent affiliate láthatóságot eredményez.
A webhelytulajdonosok többféle eszközzel szabályozhatják, hogy a keresőrobotok hogyan viselkedjenek a webhelyükön. A robots.txt fájl az elsődleges eszköz, amelyben meghatározzák, hogy mely user-agentek (robot típusok) férhetnek hozzá a webhely egyes részeihez. Egy jól konfigurált robots.txt megakadályozhatja, hogy a robotok feleslegesen feltérképezzék a duplikált tartalmakat, tesztkörnyezeteket vagy erőforrás-igényes oldalakat, miközben lehetővé teszi a fontos tartalmak szabad feltérképezését. A robots meta tag az egyes oldalak HTML-jében jelenik meg, és oldal szintű szabályozást tesz lehetővé, például egyes oldalak kizárását az indexelésből vagy a linkjeik figyelmen kívül hagyását.
A nofollow link attribútum azt jelzi a keresőrobotoknak, hogy ne kövessék az adott hiperhivatkozást – hasznos például, ha nem kívánják, hogy a robotok megbízhatatlan külső oldalakra vagy felhasználói tartalomra mutató linkeket kövessenek. Ezek a kontrollmechanizmusok együtt adják meg a finomhangolt szabályozás lehetőségét a keresőrobotok számára, miközben fenntartják a jó kapcsolatot a keresőmotorokkal. Ugyanakkor fontos tudni, hogy a rosszindulatú webes adatgyűjtők és agresszív botok gyakran figyelmen kívül hagyják ezeket a szabályokat, ezért szükséges lehet további biztonsági intézkedéseket – például sebességkorlátozást és bot felismerést – alkalmazni.
Az affiliate hálózatüzemeltetőknek és marketingeseknek alapvető fontosságú megérteni a keresőrobotok viselkedését, mivel ez közvetlenül befolyásolja az üzleti eredményeket. A keresőrobotok határozzák meg, hogy az affiliate termékoldalak, összehasonlító tartalmak és promóciós anyagok mennyire láthatók a keresési találatokban. Ha a PostAffiliatePro felhasználói optimalizálják affiliate oldalaikat a keresőrobotok számára, nő az esélyük, hogy tartalmaikat felfedezik a keresőmotorok, és releváns kulcsszavakra rangsorolódnak. Ez az organikus láthatóság minőségi forgalmat terel az affiliate ajánlatokra, növelve a konverziókat és a jutalékszerzési lehetőségeket.
Az affiliate hálózatok többféle módon profitálnak a keresőrobotok tevékenységéből. A keresőmotorok robotjai segítenek az affiliate tartalmak terjesztésében az interneten, növelve a márkaismertséget és az elérést. A robotok lehetővé teszik, hogy árösszehasonlító oldalak és tartalomaggregátorok felfedezzék és megjelenítsék az affiliate termékeket, így újabb forgalmi forrásokat teremtenek. Ugyanakkor az affiliate marketingeseknek tudatában kell lenniük a rosszindulatú keresőrobotoknak és adatgyűjtőknek is, amelyek másolhatják az affiliate tartalmakat vagy kattintási csalásban vehetnek részt. A megfelelő sebességkorlátozás, bot felismerés és tartalomvédelem alkalmazása segít megőrizni az affiliate hálózat integritását, miközben a legitim keresőrobotok akadálytalanul működhetnek.
A PostAffiliatePro átfogó követési és riportolási funkciókat kínál, amelyek jól kiegészítik a helyes keresőrobot-optimalizálást. Ha affiliate tartalmait megfelelően feltérképezik és indexelik, és ezt kombinálja a PostAffiliatePro fejlett követésével és analitikájával, maximalizálhatja affiliate hálózatának láthatóságát és jövedelmezőségét. A platform valós idejű jutalékkövetése és intelligens riportjai segítenek megérteni, mely affiliate csatornák hozzák a legértékesebb forgalmat, lehetővé téve, hogy optimalizálja hálózati stratégiáját.
Ahogyan a webes keresőrobotok rendszerezetten fedezik fel és indexelik a tartalmat, úgy követi és optimalizálja a PostAffiliatePro az affiliate kapcsolatait. Platformunk valós idejű követést, átfogó riportokat és intelligens jutalékkezelést kínál, hogy sikeres affiliate hálózatot építhessen.
A robotok (crawlers) adatokat és információkat gyűjtenek az internetről weboldalak meglátogatásával és az oldalak tartalmának olvasásával. Tudjon meg többet ról...
Tudja meg, mi az a Google Spider (Googlebot), hogyan térképezi fel és indexeli a weboldalakat, és miért nélkülözhetetlen a SEO szempontjából. Ismerje meg, hogya...
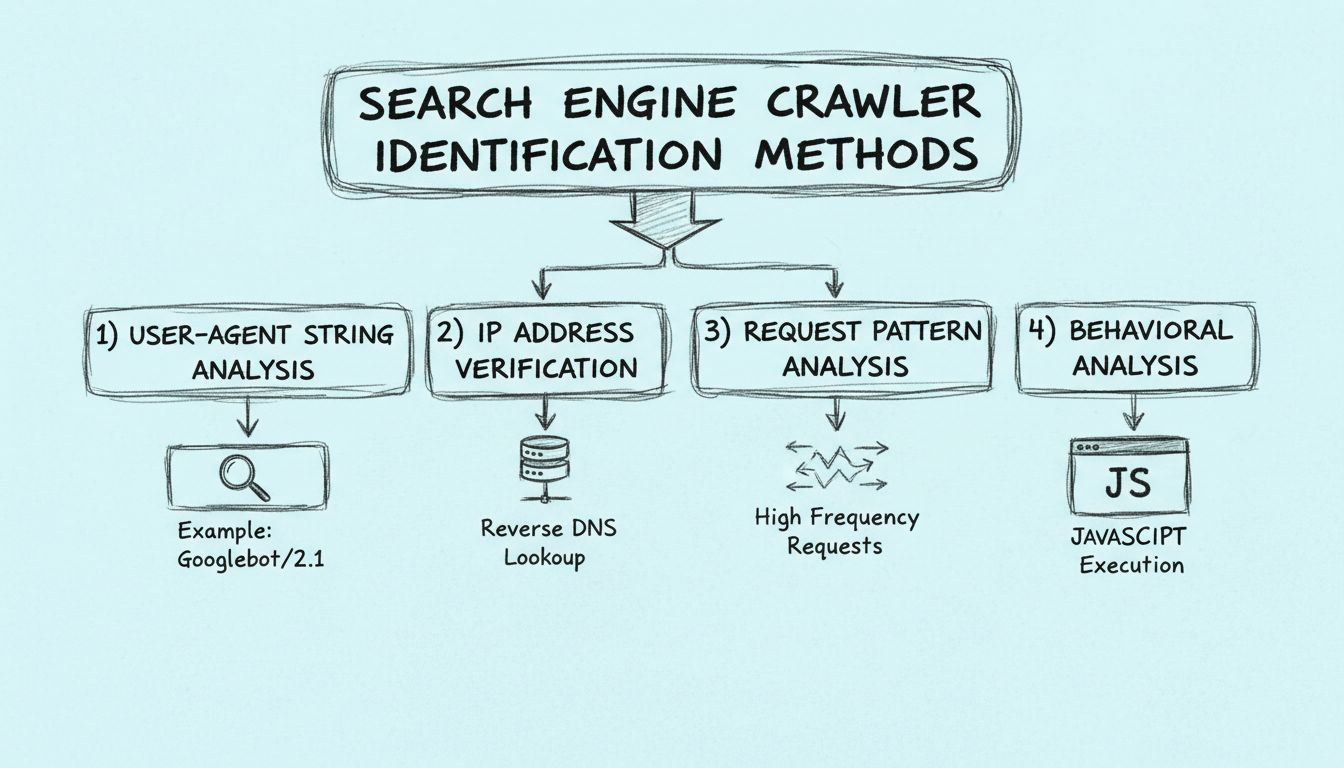
Ismerje meg, hogyan azonosíthatja a keresőmotorok robotjait user-agent stringek, IP-címek, kérések mintázata és viselkedéselemzés segítségével. Alapvető útmutat...
Csatlakozzon elégedett ügyfeleink közösségéhez és nyújtson kiváló ügyfélszolgálatot a Post Affiliate Pro-val.
Sütik Hozzájárulás
A sütiket használjuk, hogy javítsuk a böngészési élményt és elemezzük a forgalmunkat. See our privacy policy.