
Robotok és szerepük a keresőmotorok rangsorolásában
A robotok (crawlers) adatokat és információkat gyűjtenek az internetről weboldalak meglátogatásával és az oldalak tartalmának olvasásával. Tudjon meg többet ról...
5 perc olvasás
SEO
Crawlers
+4

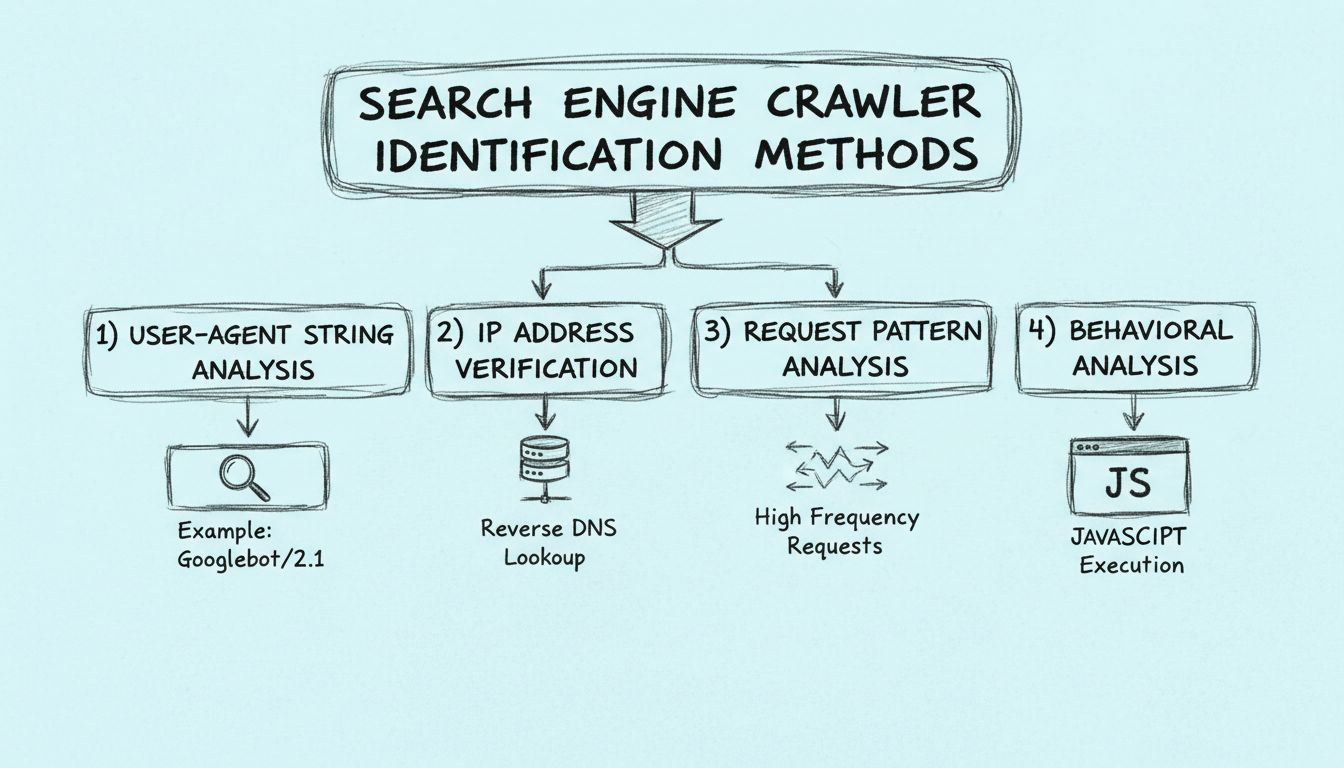
Ismerje meg, hogyan azonosíthatja a keresőmotorok robotjait user-agent stringek, IP-címek, kérések mintázata és viselkedéselemzés segítségével. Alapvető útmutató webmestereknek és fejlesztőknek.
A keresőmotorok robotjai négy fő módszerrel azonosíthatók: a HTTP fejlécekben található user-agent string elemzésével, a forrás IP-cím és a fordított DNS-hosztnév ellenőrzésével, a kérések mintázatának és gyakoriságának figyelésével, valamint a viselkedési jellemzők, például a JavaScript végrehajtási képességek vizsgálatával.
A keresőmotorok robotjai automatizált programok, amelyek rendszerszerűen böngészik az internetet, hogy felfedezzék, elemezzék és indexeljék a webes tartalmat. Ezeknek a robotoknak az azonosítása kulcsfontosságú a webmesterek, fejlesztők és affiliate marketingesek számára, akiknek meg kell érteniük weboldaluk forgalmi mintáit, és biztosítani kell a jogos keresőmotor-hozzáférést. Ellentétben a rosszindulatú botokkal, amelyek adatokat próbálnak lekaparni vagy támadásokat indítanak, a jogos keresőmotor robotok, mint például a Googlebot, Bingbot és mások, speciális technikai azonosítókkal jelzik magukat, amelyeket ellenőrizni és hitelesíteni lehet.
A jogos keresőmotor robotok és más típusú botok megkülönböztetésének képessége 2025-ben egyre fontosabbá vált, mivel a webes forgalom növekszik, és a bottevékenység egyre kifinomultabbá válik. Az azonosítási módszerek megértése segít a webhely feltérképezhetőségének optimalizálásában, az erőforrások jogosulatlan hozzáférés elleni védelmében, valamint abban, hogy az affiliate követőrendszerek pontosan különböztessék meg az organikus keresési forgalmat más forrásoktól. A PostAffiliatePro fejlett analitikai képességei segítenek a forgalmi források precíz monitorozásában és kategorizálásában, így affiliate programja pontos teljesítményadatokat rögzít.
A keresőrobotok azonosításának legegyszerűbb módja a User-Agent string vizsgálata a HTTP-kérés fejlécében. Minden HTTP-kérés tartalmaz egy User-Agent fejlécet, amely azonosítja a kérést küldő klienst, legyen az böngésző, mobilalkalmazás vagy robot. A jogos keresőmotor robotok egyedi azonosítókat tartalmaznak a User-Agent stringjeikben, amelyek egyértelműen jelzik eredetüket és céljukat. Például a Google robotja így azonosítja magát: “Googlebot/2.1 (+http://www.google.com/bot.html)”, míg a Microsoft Bing robotja: “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)”.
A User-Agent stringek elemzésekor keressen olyan mintákat és kulcsszavakat, amelyek jogos keresőrobotokra utalnak. A User-Agent string általában tartalmazza a robot nevét, verziószámát és egy linket a robot dokumentációjához vagy információs oldalához. A nagy keresőmotorok, mint a Google, Bing, Yahoo és Yandex robotjai következetes elnevezési szabályokat követnek, és ellenőrizhető információkat adnak meg céljukról. Ezeket a User-Agent stringeket naplózhatja a szerver hozzáférési naplóiban, és összevetheti az ismert keresőrobot-azonosítókkal, amelyeket a keresőmotorok és biztonsági szervezetek tartanak karban.
| Robot neve | User-Agent string példa | Keresőmotor |
|---|---|---|
| Googlebot | Googlebot/2.1 (+http://www.google.com/bot.html) | |
| Bingbot | Bingbot/2.0 (+http://www.bing.com/bingbot.htm) | Microsoft Bing |
| Slurp | Slurp/cat (+http://help.yahoo.com/help/us/ysearch/slurp) | Yahoo |
| Yandexbot | Mozilla/5.0 (compatible; YandexBot/3.0) | Yandex |
| DuckDuckBot | DuckDuckBot/1.0 (+http://duckduckgo.com/duckduckbot.html) | DuckDuckGo |
Azonban, ha kizárólag a User-Agent stringekre hagyatkozik, az korlátokba ütközik. A rosszindulatú botok ugyanis meghamisíthatják a User-Agent stringeket, hogy jogos keresőrobotnak tűnjenek, ezért elengedhetetlen ezt a módszert további ellenőrzési technikákkal kombinálni. Ezen felül előfordulhat, hogy egyes jogos robotok bizonyos helyzetekben általános vagy módosított User-Agent stringet használnak, így a keresztellenőrzés más azonosítási módszerekkel megbízhatóbb eredményt ad.
Állítsd be a fejlett nyomkövetést percek alatt. Bankkártya nem szükséges.
A keresőrobotok azonosításának második kulcsmódszere a forrás IP-cím ellenőrzése és a fordított DNS-lekérdezés. Amikor egy robot kérést küld a szerverére, az egy konkrét IP-címről érkezik, amelyet naplózni és elemezni lehet. A keresőmotorok közzéteszik a robotjaik által használt IP-címtartományokat, így a webmesterek ellenőrizhetik, hogy egy kérés valóban az adott keresőmotor infrastruktúrájából érkezik-e. A Google például részletes listát vezet a Googlebot és más Google robotok által használt IP-címekről.
A fordított DNS-lekérdezés különösen hatékony ellenőrzési technika, amely során a DNS-rendszert lekérdezi, hogy megállapítsa, mely hosztnév tartozik egy IP-címhez. Ha például egy Google-re hivatkozó IP-címen hajt végre fordított DNS-lekérdezést, akkor annak a hosztnévnek a Google domainjén belül kell lennie (például “crawl-66-249-64-1.googlebot.com”). Ezután előreirányított DNS-lekérdezéssel ellenőrizhető, hogy a hosztnév valóban ugyanarra az IP-címre mutat-e vissza – így kétirányú ellenőrzési láncot hozva létre. Ez a kétlépcsős ellenőrzési folyamat rendkívül megnehezíti a rosszindulatú szereplők számára a robotazonosság meghamisítását, hiszen ehhez mind az IP-cím, mind a hozzátartozó DNS-rekordok felett rendelkezniük kellene.
A Google hivatalos dokumentációja ezt a módszert ajánlja a Googlebot kérések legmegbízhatóbb ellenőrzési módjaként. Az eljárás során ellenőrizni kell, hogy a fordított DNS-hosztnév megfelel a Google domain-mintázatának, majd egy előreirányított DNS-lekérdezéssel vissza kell ellenőrizni, hogy ugyanarra az IP-címre mutat. Ez a módszer különösen értékes a nagy forgalmú weboldalak és affiliate hálózatok számára, ahol elengedhetetlen a pontos forgalom-hozzárendelés és a hamis bottevékenység kiszűrése a jogos keresőmotoros forgalom közül.
A kérésmintázat elemzése értékes információkat ad a robotok viselkedéséről azáltal, hogy megvizsgálja, hogyan oszlanak meg a kérések az időben és a webhely erőforrásai között. A jogos keresőmotor robotok előrejelezhető mintákat követnek, amelyek jelentősen eltérnek az emberi böngészési szokásoktól vagy a rosszindulatú botok tevékenységétől. A robotok általában egyenletes időközönként küldenek kéréseket, logikus sorrendben járják be az oldal URL-struktúráját, és tiszteletben tartják a robots.txt-ben megadott utasításokat. Ezeknek a mintáknak a monitorozásával azonosíthatja a jogos robotokat, és megkülönböztetheti őket a gyanús forgalomtól.
A mintázatok elemzésekor több kulcsfontosságú jellemzőre figyeljen, amelyek a jogos robotviselkedésre utalnak. Először vizsgálja a kérések gyakoriságát és eloszlását – a jogos robotok általában úgy időzítik a kéréseiket, hogy ne terheljék túl a szervert, gyakran exponenciális visszalépési algoritmusokat követve, amelyek lassítanak, ha HTTP 500-as hibákat vagy más szerverterhelési jeleket kapnak. Másodszor, elemezze az URL-bejárási mintát – a jogos robotok rendszerszerűen követik a linkeket és tiszteletben tartják a webhely struktúráját, míg a rosszindulatú botok gyakran véletlenszerű vagy sorozatos kéréseket küldenek nem létező vagy nem linkelt URL-ekre. Harmadszor, figyelje meg a kért erőforrások típusát – a jogos robotok jellemzően HTML oldalakat, CSS és JavaScript fájlokat kérnek le, amelyek szükségesek az oldalak megjelenítéséhez, miközben kerülik a felesleges bináris fájlokat vagy érzékeny könyvtárakat.
A kérésmintázat-figyelést megvalósíthatja szervernaplók elemzésével, így azonosíthatja azokat a kéréscsoportokat, amelyek közös jellemzőkkel bírnak. Olyan eszközök, mint a webanalitikai platformok és a szervernapló-elemző szoftverek automatizálhatják ezt a folyamatot, és figyelmeztethetnek a szokatlan mintákra. Például, ha egyetlen IP-cím percenként 1000 kérést küld különböző termékoldalakra sorban, valószínűleg robotról van szó. Ezzel szemben a jogos keresőrobotok sokkal alacsonyabb gyakorisággal küldik a kéréseket, gyakran néhány másodperc szünettel, hogy kíméljék a szerver erőforrásait és elkerüljék a korlátozási mechanizmusok aktiválását.
Értesülj elsőként az új funkciókról és termékfrissítésekről.
A viselkedéselemzés azt vizsgálja, hogyan lépnek kölcsönhatásba a robotok a webhely tartalmával és technológiai környezetével, így lehetővé teszi a jogos keresőmotor robotok és más botok elkülönítését. Az egyik legfontosabb viselkedési jellemző a JavaScript végrehajtási képesség. A modern keresőmotorok, például a Google, headless böngészőt (például a Chrome-hoz hasonlót) használnak az oldalak renderelésére, hogy végrehajtsák a JavaScriptet és hozzáférjenek a dinamikusan generált tartalomhoz. Ez azt jelenti, hogy a jogos robotok végrehajtják a JavaScript kódot az oldalakon, míg sok rosszindulatú bot vagy egyszerű scraper nem képes vagy nem hajt végre JavaScriptet.
A JavaScript végrehajtás észleléséhez helyezzen el olyan követőkódot, amely csak akkor fut le, ha a JavaScript engedélyezett és működőképes. Ha egy kérés eléri az oldalt, de nem indít el JavaScript-alapú követést vagy nem tölti be a dinamikus tartalmat, az arra utal, hogy a kérelmező nem egy modern keresőrobot. Ezenkívül a jogos robotok általában az összes olyan erőforrást lekérik, amelyek szükségesek az oldal teljes rendereléséhez, beleértve a képeket, stíluslapokat és JavaScript fájlokat, míg az egyszerű botok gyakran csak a HTML fájlt kérik le, a kísérő erőforrásokat nem töltik be.
Egy másik fontos viselkedési jel a robotok interaktív elemekhez és űrlapokhoz való viszonya. A jogos keresőmotor robotok nem küldenek be űrlapokat, nem kattintanak gombokra, és nem lépnek kölcsönhatásba a dinamikus tartalommal olyan módon, amely nem kívánt mellékhatásokat okozna, például rendelést adnának le vagy adatokat módosítanának. Tartalom olvasására és elemzésére koncentrálnak, és nem interakcióra. A rosszindulatú botok ezzel szemben gyakran próbálnak űrlapokat kitölteni, adatokat beküldeni vagy olyan műveleteket indítani, amelyek árthatnak a webhelynek, vagy adatokat lophatnak. Ezeknek a viselkedési mintáknak a monitorozásával azonosíthatja a jogosulatlan interakciókat kezdeményező kéréseket, és megkülönböztetheti őket a jogos robottevékenységtől.
A leghatékonyabb robotazonosítási megközelítés mind a négy módszert egy átfogó ellenőrzési munkafolyamatba integrálja. Egyetlen azonosítási módszerre támaszkodás helyett a rétegezett ellenőrzési rendszer robusztus védelmet nyújt a meghamisított robotok ellen, és biztosítja a pontos forgalom-hozzárendelést. Kezdje a User-Agent string és az IP-cím minden kérésnél történő rögzítésével, majd vesse össze ezeket az ismert keresőrobot-adatbázisokkal, amelyeket keresőmotorok és biztonsági szervezetek tartanak karban. Ezután végezzen fordított DNS-lekérdezést annak ellenőrzésére, hogy az IP-címhez tartozó hosztnév megfelel-e az állított keresőmotor domainjének. Végül elemezze a kérésmintázatot és a viselkedési jellemzőket, hogy a tevékenység valóban jogos robotviselkedést tükröz-e.
Ez a többrétegű megközelítés különösen fontos affiliate hálózatok és teljesítményalapú marketingplatformok, például a PostAffiliatePro számára, ahol a pontos forgalom-hozzárendelés közvetlen hatással van a jutalékszámításokra és a program integritására. Átfogó robotazonosítás bevezetésével biztosíthatja, hogy affiliate követőrendszerei pontosan különböztessék meg a jogos keresőmotoros forgalmat, a fizetett hirdetési forgalmat és az organikus felhasználói forgalmat. Ez a pontosság jobb teljesítmény-elemzést, pontosabb ROI-számítást és fejlettebb csalásészlelő képességeket tesz lehetővé.
A modern webes infrastruktúra kifinomult robotazonosítási rendszereket igényel, amelyek képesek kezelni a mai webforgalom összetettségét. Először is, tartson naprakész listát a jogos robotok IP-címeiről és User-Agent stringjeiről, hivatalos értesítésekre feliratkozva a nagy keresőmotoroktól. A Google, Bing és más keresőmotorok közzéteszik, ha új robotokat indítanak vagy módosítják infrastruktúrájukat, és ezek nyomon követése biztosítja, hogy az azonosítási rendszerei aktuálisak maradjanak. Másodszor, vezessen szerveroldali naplózást, amely minden releváns kérésmetaadatot rögzít, beleértve a User-Agent stringeket, IP-címeket, időbélyegeket és a kért erőforrásokat. Ezek az adatok alapját képezik a mintázatelemzésnek és viselkedésfigyelésnek.
Harmadszor, fontolja meg robotazonosító API vagy szolgáltatás bevezetését, amely valós időben automatikusan validálja a robotazonosságot. Számos biztonsági és analitikai platform kínál már olyan azonosítási szolgáltatásokat, amelyek naprakész adatbázisokat tartanak fenn a jogos robotokról, és ezekhez viszonyítva ellenőrzik a kéréseket. Negyedszer, alakítson ki egyértelmű irányelveket az ismeretlen vagy gyanús robottevékenység kezelésére. Dönthet úgy, hogy ezeket a kéréseket normálisan szolgálja ki, miközben naplózza őket elemzésre, vagy bevezethet korlátozásokat az erőforrás-kimerítés megelőzésére. Végül, rendszeresen vizsgálja felül és frissítse robotazonosítási szabályait és küszöbértékeit a megfigyelt forgalmi minták és az új fenyegetések alapján. A webes robotizálás folyamatosan fejlődik, ezért az azonosítási rendszereinek is alkalmazkodniuk kell a hatékonyság fenntartása érdekében.
A keresőmotorok robotjainak azonosítása több ellenőrzési módszer átfogó ismeretét és azok hatékony kombinálását igényli. A User-Agent stringek elemzésével, az IP-címek fordított DNS-lekérdezéses ellenőrzésével, a kérésmintázatok monitorozásával és a viselkedési jellemzők vizsgálatával megbízhatóan elkülönítheti a jogos keresőmotor robotokat más botoktól és forgalmi forrásoktól. Ez a képesség elengedhetetlen a webmesterek, fejlesztők és affiliate marketingesek számára, akiknek érteniük kell forgalmi forrásaikat és biztosítaniuk kell a pontos teljesítménykövetést. A PostAffiliatePro fejlett analitikai és forgalomfigyelő képességei segítenek e módszerek hatékony alkalmazásában, így affiliate programja pontos adatokat rögzít, és megőrzi programja integritását az egyre összetettebb digitális környezetben.
A PostAffiliatePro a vezető partnerkezelő szoftver, amely segít pontosan követni, kezelni és optimalizálni partnerhálózatát. Azonosítsa a valós forgalmi forrásokat, és maximalizálja partnerprogramja teljesítményét fejlett analitikával és valós idejű monitorozással.
A robotok (crawlers) adatokat és információkat gyűjtenek az internetről weboldalak meglátogatásával és az oldalak tartalmának olvasásával. Tudjon meg többet ról...

Ismerje meg, hogyan működnek a webes keresőrobotok a kezdő URL-ektől az indexelésig. Értse meg a technikai folyamatokat, a keresőrobotok típusait, a robots.txt ...
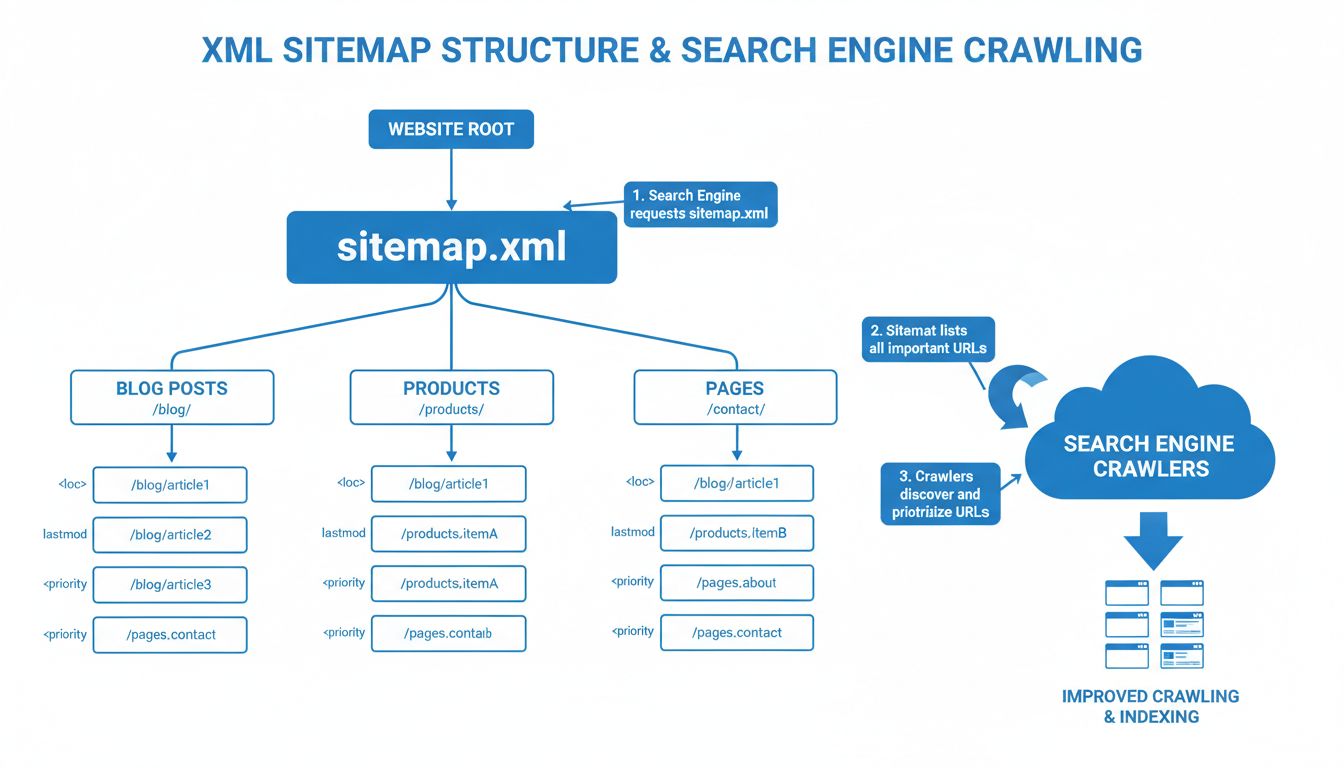
Tudd meg, miért kulcsfontosságúak a webhelytérképek az SEO sikeréhez. Fedezd fel, hogyan javítják az XML és HTML webhelytérképek a feltérképezhetőséget, indexel...
Csatlakozzon elégedett ügyfeleink közösségéhez és nyújtson kiváló ügyfélszolgálatot a Post Affiliate Pro-val.
Sütik Hozzájárulás
A sütiket használjuk, hogy javítsuk a böngészési élményt és elemezzük a forgalmunkat. See our privacy policy.